刷过《剑指Offer》的同学,想必都会对这道题有印象,但是如果你之前是在牛客网或者AcWing其他的网站做这道题,那么即便AC通过了所有的测试,你的答案也可能是错误的。我自己之前也是被这个答案误导过,下面我来详细地解释一下自己曾经写过的错误代码,以免以后再次犯同样的错误。
请设计一个函数,用来判断在一个矩阵中是否存在一条包含某字符串所有字符的路径。路径可以从矩阵中的任意一个格子开始,每一步可以在矩阵中向左,向右,向上,向下移动一个格子。如果一条路径经过了矩阵中的某一个格子,则之后不能再次进入这个格子。 例如 a b c e s f c s a d e e 这样的3 X 4 矩阵中包含一条字符串”bcced”的路径,但是矩阵中不包含”abcb”路径,因为字符串的第一个字符b占据了矩阵中的第一行第二个格子之后,路径不能再次进入该格子。
我从Python的排行榜中复制出来了一个比较“流行”的写法。代码如下,这个代码有两处错误。
1 | def hasPath(self, matrix, rows, cols, path): |
其中一处错误很明显。在函数find中,他选择了右左下上的顺序,那么如果右边开始匹配,并且右边匹配上了一个字符,那么会继续递归,最后结果如果返回了False,那么接下来的左下上就会被跳过,错误地返回了False。我们来举个栗子🌰。
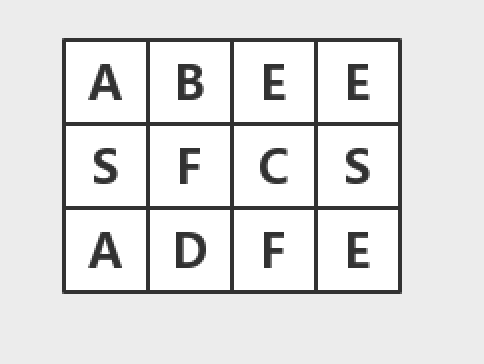
如果矩阵如上图中那样,并且开始寻找字符转SEE。根据上述算法,当找到S时,先选择往下走,找到了一个E,然后返回了False,忽略了上面的SEE。
于是我将find方法改成了下面这样。
1 | def find(matrix, rows, cols, path, i, j): |
这之后的很长一段时间,我一直以为这个写法是正确的。直到我在LeetCode上发现这道原题,自信满满地提交自己认为正确的答案,被这个TestCase教做人。我当时提交的完整答案是这样的。这个输入参数有一些不一样的地方,LeetCode输入的是二维数组,牛客是一个字符串,这里写的是LeetCode的写法。这里因为是二维数组,所以要做深拷贝。
1 | def exist(self, g: List[List[str]], word: str) -> bool: |
未通过的TestCase为:目标字符串为ABCESEEEFS。
为了方便观察问题,我加了两行输出。
1 | cur -> (0, 0) BCESEEEFS, [['-', 'B', 'C', 'E'], ['S', 'F', 'E', 'S'], ['A', 'D', 'E', 'E']] |
这个稍微看一下就明白了,虽然每次匹配第一个字符串A的时候传入了一个新的二维数组,但是在找A之后的路径时,每次返回False的时候没有将-恢复成原来的字母。下面请记住我代码中写的方向顺序为上下左右。

在上面的几步延伸之后,回到了ABC然后右边的字母没有恢复,所以返回了False。于是我们可以先记录一下之前的字母,然后在得到结果后将其恢复。
1 | def exist(self, g: List[List[str]], word: str) -> bool: |
输出为:
1 | cur -> (0, 0) BCESEEEFS, [['-', 'B', 'C', 'E'], ['S', 'F', 'E', 'S'], ['A', 'D', 'E', 'E']] |
这个例子非常复杂也非常棒,由衷感谢提交这个TestCase的人让我意识到自己的愚蠢,此例子一共做了4次尝试,让我们用图解的方式来还原一下。因为是上下左右这个顺序,所以尝试过程如下:
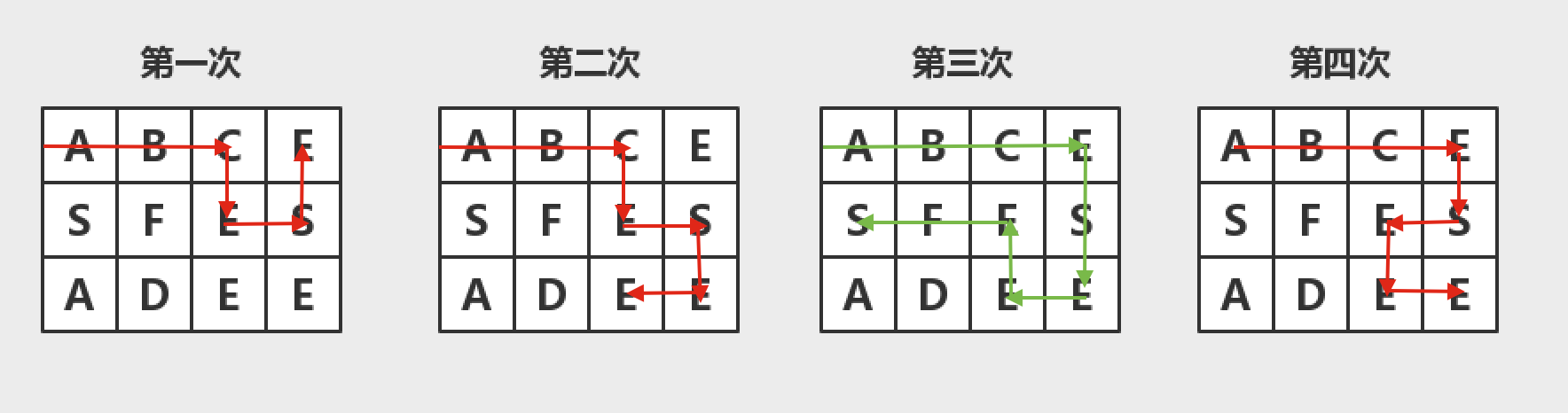
这一次,我们代码可能通过功能测试了,但是想想如果每个匹配第一个字符串都深拷贝一个数组,如果数组特别大,那么将耗费大量时间,其实我们在做好恢复工作后就不需要在拷贝数组了。将其去掉后:
1 | def exist(self, g: List[List[str]], word: str) -> bool: |
自信提交后,又被这样一个TestCase教育了,返回超时。
1 | [["a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a"],["a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a"],["a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a"],["a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a"],["a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a"],["a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a"],["a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a"],["a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a","a"],["a","a","a","a","a","a... |
想了半天终于明白,我在四个方向寻找是否可以延伸时,只要有一个方向可以,那么我就无需再判断其他方向了。
所以这里加一个break即可。
1 | def exist(self, g: List[List[str]], word: str) -> bool: |
以上就是最终的代码,试了一下LeetCode评论区的高票代码,其中有一个写法,将主循环的g[i][j]==word[0]移到了spread中判断,个人觉得这个是为什么比它快了100ms以上的原因。此文中的最终方法AC188ms,而那个代码需要336ms。
通过一番深入的分析,自己对于回溯有了更深一步的认识,同时也明白了一个深刻的道理,不要轻信他人的代码,包括此文中的也是。